Данная статья посвящена теме генерации хеш-кодов на платформе .NET. Тема является достаточно интересной, и думаю любой уважающий себя .NET разработчик должен ее знать. Поэтому поехали!
Начнем нашу статью с того, что узнаем что хранится у объектов ссылочного типа помимо их полей.
У каждого объекта ссылочного типа есть так называемый заголовок (Header), который состоит из двух полей: указатель на тип которым является данный объект (MethodTablePointer), а так же индекс синхронизации (SyncBlockIndex).
Для чего они нужны?
Первое поле необходимо для того, чтобы каждый управляемый объект мог предоставить информацию о своем типе во время выполнения, то есть нельзя выдать один тип за другой, это сделано для безопасности типов. Так же этот указатель используется для реализации динамической диспетчеризации методов, фактически через него вызываются методы данного объекта. Метод Object.GetType фактически возвращает именно указатель MethodTablePointer.
Второе поле необходимо для многопоточного окружения, а именно для того чтобы каждый объект можно было использовать потокобезопасно.
Когда загружается CLR, она создает так называемый пул блоков синхронизации, можно сказать обычный массив этих блоков синхронизации. Когда объекту необходимо работать в многопоточном окружении (это делается с помощью метода Monitor.Enter или конструкции языка C# lock), CLR отыскивает свободный блок синхронизации в своем списке и записывает его индекс в то самое поле в заголовке объекта. Как только объект перестает нуждаться в многопоточном окружение, CLR просто присваивает значение -1 этому полю и тем самым освобождает блок синхронизации.
Блоки синхронизации — это фактически новое воплощение критических секций из С++. Создатели CLR посчитали, что ассоциировать с каждым управляемым объектом структуру критической секции будет слишком накладно, учитывая, что большинство объектов вообще не используют многопоточное окружение.
Для большего понимания ситуации рассмотрим следующую картинку:
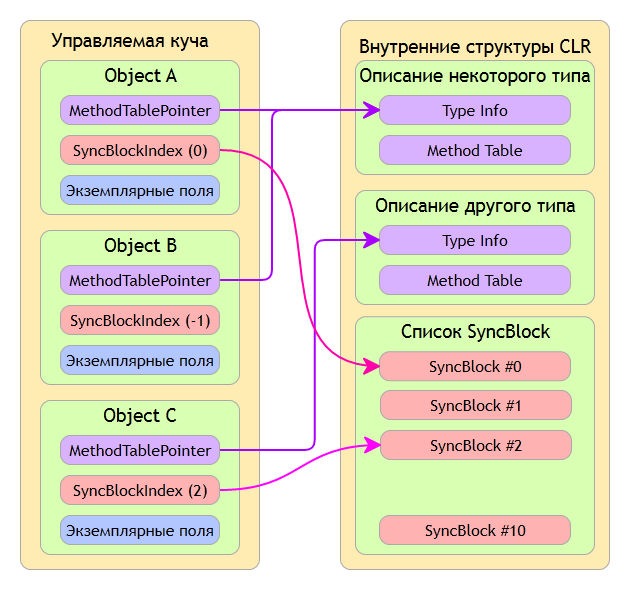
По картинке видно, что ObjectA и ObjectB имеют один тип, поскольку их MethodTablePointer-ы указывают на один и тот же тип. ObjectC же имеет другой тип. Так же видно, что ObjectA и ObjectC задействуют пул блоков синхронизации, то есть фактически используют многопоточное окружение. ObjectB не использует пул поскольку его SyncBlockIndex = -1.
Теперь после того как мы рассмотрели как хранятся объекты, мы можем перейти к генерации хеш-кодов.
Я не зря начал статью с объяснения того, что такое SyncBlock, поскольку в первых версиях фреймворка в качестве хеш-кода ссылочного типа использовался именно свободный индекс некоторого SyncBlock-а. Таким образом, в .NET 1.0 и .NET 1.1 вызов метода GetHashCode приводил к созданию SyncBlock и занесением его индекса в заголовок объекта в поле SyncBlockIndex. Как вы понимаете это не очень хорошая реализация для хеш-функции, поскольку во-первых создаются не нужные внутренние структуры, которые занимают память + тратиться время на их создание, во-вторых хеш-коды будут идти подряд, то есть будут предсказуемыми. Вот ссылка на блог, в котором один из разработчиков CLR говорит, что такая реализация плохая, и что они ее поменяют в следующей версии.
Начиная с .NET 2.0 алгоритм хеширования изменился. Теперь он использует manage идентификатор потока, в котором выполняется метод. Если верить реализации в SSCLI20, то метод выглядит так:
Как и раньше хеш-код вычисляется один раз и сохраняется в заголовке объекта в поле SyncBlockIndex (это оптимизация CLR). Теперь возникает вопрос, что если после вызова метода GetHashCode нам понадобиться использовать индекс синхронизации? Куда его записывать? И что делать с хеш-кодом?
Для ответа на эти вопросы рассмотрим структуру SyncBlock.
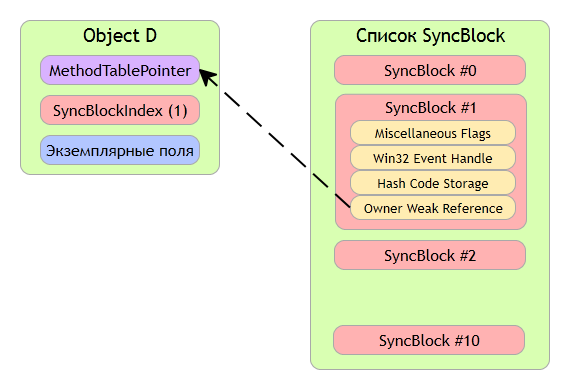
При первом вызове метода GetHashCode CLR вычисляет хеш-код и заносит его в поле SyncBlockIndex. Если при этом с объектом ассоциирован SyncBlock, то есть поле SyncBlockIndex используется, то CLR записывает хеш-код в сам SyncBlock, на рисунке показано место в SyncBlock, отвечающее за хранение хеш-кода. Как только SyncBlock освобождается, CLR копирует хеш-код из его тела в заголовок объекта SyncBlockIndex. Вот и все.
Теперь поговорим о том, как работает метод GetHashCode у значимых типов. Скажу заранее, он работает достаточно интересно.
Первое, что надо сказать так это то, что создатели CLR рекомендуют всегда переопределять данный метод у пользовательских типов, поскольку он может работать не очень быстро, да и поведение его по умолчанию, возможно, не всегда Вас удовлетворит.
На самом деле у CLR есть две версии реализации метода GetHashCode для значимых типов, и то какая версия будет использована, исключительно зависит от самого типа.
Первая версия:
Если структура не имеет ссылочных полей, а так же между ее полями нет свободного места, то используется быстрая версия метода GetHashCode. CLR просто xor — ит каждый 4 байта структуры и получает ответ. Это хороший хеш, так как задействовано всё содержимое структуры. Например, структура, у которой есть поле типа bool и int будет иметь свободное пространство в 3 байта, поскольку JIT когда размещает поля выравнивает их по 4 байта, а, следовательно, будет использована вторая версия для получения хеш-кода.
Кстати, в реализации данной версии был баг, который исправлен только в .NET 4. Он заключается в том, что хеш-код для типа decimal вычислялся не правильно.
Рассмотрим код
Вторая версия:
Если структура содержит ссылочные поля или между ее полями имеется свободное пространство, то используется медленная версия метода. CLR выбирает первое поле структуры, на основание которого и создает хеш-код. Это поле по возможности должно быть неизменяемым, например, иметь тип string, иначе при его изменении хеш-код будет так же меняться, и мы не сможем уже найти нашу структуру в хеш-таблице, если она использовалась в качестве ключа. Получается, если первое поле структуры будет изменяемым, то это ломает стандартную логику метода GetHashCode. Это еще одна причина по которой структуры должны быть не изменяемыми. CLR xor-ит хеш-код данного поля с указателем на тип данного поля (MethodTablePointer). CLR не рассматривает статические поля, так как статичным полем может быть поле с данным же типов, в результате чего мы впадем в бесконечную рекурсию.
Структуры не могут содержать экземплярные поля своего же типа. То есть следующий код не будет компилироваться:
Чтобы понять ситуацию лучше рассмотрим следующий код:
k1 — 411217769, k2 — 411217771
Во втором же случае, у структуры есть ссылочное поле (string), поэтому используется медленная версия. CLR в качестве поля для генерации хеш- кода выбирает поле с типом int, а строковое поле просто игнорируется в результате чего на консоль будет выведено следующее:
v1 — 411217780, v2 — 411217780
Теперь думаю понятно, почему разработчики CLR говорят, чтобы все пользовательские значимые типы данных (да и не только значимые, а все вообще) переопределяли метод GetHashCode. Во-первых, он может работать не очень быстро, во-вторых, чтобы избежать непонимания того, почему хеш-коды разных объектов равны, как во втором случае примера.
Если не переопределить метод GetHashCode можно получить большой удар по производительности при использование значимого типа в качестве ключа в хеш-таблице.
Класс String переопределяет метод GetHashCode. Его реализация в.NET 4.5 выглядит так:
Это код для 64 разрядной машины, но если взглянем на общий код с директивами
то заметим, что имеются отличия в зависимости от того какая машина 32 или 64 разрядная.
Следует сказать, что реализация данного метода меняется с каждым выходом .NET. Об этом писал Эрик Липперт. Он предупреждал, чтобы наш код ни в коем случае не сохранял хеши, которые сгенерированы стандартным путем в базе данных или на диске, поскольку они, скорее всего, поменяют реализацию в следующем выпуски .NET. Так оно и происходило на протяжения последних 4 выпусков .NET.
Реализация хеширования у строкового типа не подразумевает кэширования результата. То есть каждый раз при вызове метода GetHashCode мы будем заново вычислять хеш-код для строки. По словам Эрика Липперта, это сделано чтобы сэкономить память, лишние 4 байта для каждого объекта строкового типа того не стоят. Учитывая, что реализация очень быстрая, думаю это правильное решение.
Если вы заметили, в реализации метода GetHashCode появился код, которого раньше не было:
Прежде чем переходить к рассмотрению реализации метода GetHashCode у делегатов поговорим о том, как они реализованы.
Каждый делегат наследуется от класса MulticastDelegate, который в свою очередь наследуется от класса Delegate. Эта иерархия сложилась исторически, поскольку можно было бы обойтись одним классом MulticastDelegate.
Реализация метода GetHashCode в классе Delegate выглядит так
Как известно, делегаты могут содержать цепочки методов, то есть вызов одного делегата приведет к вызову несколько методов, в таком случае такая реализация не годится так как у делегатов одного типа не зависимо от количества методов был бы один хеш-код, что не совсем хорошо, поэтому в MulticastDelegate метод GetHashCode переопредели таким образом, что он задействует каждый метод лежащий в основе делегата. Однако если количество методов и тип делегатов все же совпадают, то хеш-коды будут так же одинаковы.
Реализация метода в классе MulticastDelegate выглядит так
Если делегат содержит только один метод, то в коде выше objArray = null и соответственно хеш-код делегата будет равен хеш-коду типа делегата.
Как известно, анонимные типы — это новая фича в языке C# 3.0. Причем, это именно фича языка, так называемый синтаксический сахар поскольку CLR о них ничего не знает.
Метод GetHashCode у них переопределен таким образом, что использует каждое поле. Используя такую реализацию, два анонимных типа возвращают одинаковый хеш-код в том и только в том случае если их все поля равны. Такая реализация делает анонимные типы хорошо подходящими для ключей в хеш-таблицах.
Учитывая, что метод GetHashCode переопределен метод Equals, так же должен быть переопределен соответствующим образом.
method Equals return true
operator == return false
Все дело в том, что анонимные типы переопределяют метод Equals таким образом, что он проверяет все поля как это сделано у ValueType (только без рефлексии), но не переопределяет оператор равенства. Таким образом, метод Equals сравнивает по значению, в то время как оператор равенства сравнивает по ссылкам.
Для чего надо было переопределять методы Equals и GetHashCode?
Учитывая, что анонимные типы были созданы для упрощения работы с LINQ, ответ становится понятным. Анонимные типы удобно использовать в качестве хеш-ключей в операциях группировки (group) и соединения (join) в LINQ.
Как видите генерация хеш-кодов — дело весьма не простое. Для того чтобы сгенерировать хорошие хеши, нужно приложить не мало усилий, и разработчикам CLR пришлось пойти на многие уступки, чтобы облегчить нам жизнь. Сгенерировать хеш-код хорошо, для всех случаев невозможно, поэтому лучше переопределять метод GetHashCode для ваших пользовательских типов, тем самым подстраивая их к конкретной вашей ситуации.
Спасибо за прочтение! Надеюсь, статья оказалось полезной.
Что хранится в объектах помимо их полей?
Начнем нашу статью с того, что узнаем что хранится у объектов ссылочного типа помимо их полей.
У каждого объекта ссылочного типа есть так называемый заголовок (Header), который состоит из двух полей: указатель на тип которым является данный объект (MethodTablePointer), а так же индекс синхронизации (SyncBlockIndex).
Для чего они нужны?
Первое поле необходимо для того, чтобы каждый управляемый объект мог предоставить информацию о своем типе во время выполнения, то есть нельзя выдать один тип за другой, это сделано для безопасности типов. Так же этот указатель используется для реализации динамической диспетчеризации методов, фактически через него вызываются методы данного объекта. Метод Object.GetType фактически возвращает именно указатель MethodTablePointer.
Второе поле необходимо для многопоточного окружения, а именно для того чтобы каждый объект можно было использовать потокобезопасно.
Когда загружается CLR, она создает так называемый пул блоков синхронизации, можно сказать обычный массив этих блоков синхронизации. Когда объекту необходимо работать в многопоточном окружении (это делается с помощью метода Monitor.Enter или конструкции языка C# lock), CLR отыскивает свободный блок синхронизации в своем списке и записывает его индекс в то самое поле в заголовке объекта. Как только объект перестает нуждаться в многопоточном окружение, CLR просто присваивает значение -1 этому полю и тем самым освобождает блок синхронизации.
Блоки синхронизации — это фактически новое воплощение критических секций из С++. Создатели CLR посчитали, что ассоциировать с каждым управляемым объектом структуру критической секции будет слишком накладно, учитывая, что большинство объектов вообще не используют многопоточное окружение.
Для большего понимания ситуации рассмотрим следующую картинку:
По картинке видно, что ObjectA и ObjectB имеют один тип, поскольку их MethodTablePointer-ы указывают на один и тот же тип. ObjectC же имеет другой тип. Так же видно, что ObjectA и ObjectC задействуют пул блоков синхронизации, то есть фактически используют многопоточное окружение. ObjectB не использует пул поскольку его SyncBlockIndex = -1.
Теперь после того как мы рассмотрели как хранятся объекты, мы можем перейти к генерации хеш-кодов.
Как работает GetHashCode у ссылочных типов
То, что метод GetHashCode возвращает адрес объекта в управляемой куче — это миф. Этого быть не может, в виду его не постоянства, сборщик мусора, уплотняя кучу, смещает объекты и соответственно меняет им всем адреса.
Я не зря начал статью с объяснения того, что такое SyncBlock, поскольку в первых версиях фреймворка в качестве хеш-кода ссылочного типа использовался именно свободный индекс некоторого SyncBlock-а. Таким образом, в .NET 1.0 и .NET 1.1 вызов метода GetHashCode приводил к созданию SyncBlock и занесением его индекса в заголовок объекта в поле SyncBlockIndex. Как вы понимаете это не очень хорошая реализация для хеш-функции, поскольку во-первых создаются не нужные внутренние структуры, которые занимают память + тратиться время на их создание, во-вторых хеш-коды будут идти подряд, то есть будут предсказуемыми. Вот ссылка на блог, в котором один из разработчиков CLR говорит, что такая реализация плохая, и что они ее поменяют в следующей версии.
Начиная с .NET 2.0 алгоритм хеширования изменился. Теперь он использует manage идентификатор потока, в котором выполняется метод. Если верить реализации в SSCLI20, то метод выглядит так:
inline DWORD GetNewHashCode()
{
// Every thread has its own generator for hash codes so that we won't get into a situation
// where two threads consistently give out the same hash codes.
// Choice of multiplier guarantees period of 2**32 - see Knuth Vol 2 p16 (3.2.1.2 Theorem A)
DWORD multiplier = m_ThreadId*4 + 5;
m_dwHashCodeSeed = m_dwHashCodeSeed*multiplier + 1;
return m_dwHashCodeSeed;
}Как и раньше хеш-код вычисляется один раз и сохраняется в заголовке объекта в поле SyncBlockIndex (это оптимизация CLR). Теперь возникает вопрос, что если после вызова метода GetHashCode нам понадобиться использовать индекс синхронизации? Куда его записывать? И что делать с хеш-кодом?
Для ответа на эти вопросы рассмотрим структуру SyncBlock.
При первом вызове метода GetHashCode CLR вычисляет хеш-код и заносит его в поле SyncBlockIndex. Если при этом с объектом ассоциирован SyncBlock, то есть поле SyncBlockIndex используется, то CLR записывает хеш-код в сам SyncBlock, на рисунке показано место в SyncBlock, отвечающее за хранение хеш-кода. Как только SyncBlock освобождается, CLR копирует хеш-код из его тела в заголовок объекта SyncBlockIndex. Вот и все.
Как работает GetHashCode у значимых типов
Теперь поговорим о том, как работает метод GetHashCode у значимых типов. Скажу заранее, он работает достаточно интересно.
Первое, что надо сказать так это то, что создатели CLR рекомендуют всегда переопределять данный метод у пользовательских типов, поскольку он может работать не очень быстро, да и поведение его по умолчанию, возможно, не всегда Вас удовлетворит.
На самом деле у CLR есть две версии реализации метода GetHashCode для значимых типов, и то какая версия будет использована, исключительно зависит от самого типа.
Первая версия:
Если структура не имеет ссылочных полей, а так же между ее полями нет свободного места, то используется быстрая версия метода GetHashCode. CLR просто xor — ит каждый 4 байта структуры и получает ответ. Это хороший хеш, так как задействовано всё содержимое структуры. Например, структура, у которой есть поле типа bool и int будет иметь свободное пространство в 3 байта, поскольку JIT когда размещает поля выравнивает их по 4 байта, а, следовательно, будет использована вторая версия для получения хеш-кода.
Кстати, в реализации данной версии был баг, который исправлен только в .NET 4. Он заключается в том, что хеш-код для типа decimal вычислялся не правильно.
Рассмотрим код
decimal d1 = 10.0m;
decimal d2 = 10.00000000000000000m;Вторая версия:
Если структура содержит ссылочные поля или между ее полями имеется свободное пространство, то используется медленная версия метода. CLR выбирает первое поле структуры, на основание которого и создает хеш-код. Это поле по возможности должно быть неизменяемым, например, иметь тип string, иначе при его изменении хеш-код будет так же меняться, и мы не сможем уже найти нашу структуру в хеш-таблице, если она использовалась в качестве ключа. Получается, если первое поле структуры будет изменяемым, то это ломает стандартную логику метода GetHashCode. Это еще одна причина по которой структуры должны быть не изменяемыми. CLR xor-ит хеш-код данного поля с указателем на тип данного поля (MethodTablePointer). CLR не рассматривает статические поля, так как статичным полем может быть поле с данным же типов, в результате чего мы впадем в бесконечную рекурсию.
На заметку
Структуры не могут содержать экземплярные поля своего же типа. То есть следующий код не будет компилироваться:
public struct Node
{
int data;
Node node;
}var myNode = new Node();
myNode.node.node.node.node.node.node.node.node.node.......public struct Node
{
int data;
static Node node;
}На заметку
Чтобы понять ситуацию лучше рассмотрим следующий код:
var k1 = new KeyValuePair<int, int>(10, 29);
var k2 = new KeyValuePair<int, int>(10, 31);
Console.WriteLine("k1 - {0}, k2 - {1}", k1.GetHashCode(), k2.GetHashCode());
var v1 = new KeyValuePair<int, string>(10, "abc");
var v2 = new KeyValuePair<int, string>(10, "def");
Console.WriteLine("v1 - {0}, v2 - {1}", v1.GetHashCode(), v2.GetHashCode());k1 — 411217769, k2 — 411217771
Во втором же случае, у структуры есть ссылочное поле (string), поэтому используется медленная версия. CLR в качестве поля для генерации хеш- кода выбирает поле с типом int, а строковое поле просто игнорируется в результате чего на консоль будет выведено следующее:
v1 — 411217780, v2 — 411217780
Теперь думаю понятно, почему разработчики CLR говорят, чтобы все пользовательские значимые типы данных (да и не только значимые, а все вообще) переопределяли метод GetHashCode. Во-первых, он может работать не очень быстро, во-вторых, чтобы избежать непонимания того, почему хеш-коды разных объектов равны, как во втором случае примера.
Если не переопределить метод GetHashCode можно получить большой удар по производительности при использование значимого типа в качестве ключа в хеш-таблице.
Как работает GetHashCode у строкового типа
Класс String переопределяет метод GetHashCode. Его реализация в.NET 4.5 выглядит так:
Это код для 64 разрядной машины, но если взглянем на общий код с директивами
то заметим, что имеются отличия в зависимости от того какая машина 32 или 64 разрядная.
Следует сказать, что реализация данного метода меняется с каждым выходом .NET. Об этом писал Эрик Липперт. Он предупреждал, чтобы наш код ни в коем случае не сохранял хеши, которые сгенерированы стандартным путем в базе данных или на диске, поскольку они, скорее всего, поменяют реализацию в следующем выпуски .NET. Так оно и происходило на протяжения последних 4 выпусков .NET.
Реализация хеширования у строкового типа не подразумевает кэширования результата. То есть каждый раз при вызове метода GetHashCode мы будем заново вычислять хеш-код для строки. По словам Эрика Липперта, это сделано чтобы сэкономить память, лишние 4 байта для каждого объекта строкового типа того не стоят. Учитывая, что реализация очень быстрая, думаю это правильное решение.
Если вы заметили, в реализации метода GetHashCode появился код, которого раньше не было:
if (HashHelpers.s_UseRandomizedStringHashing)
return string.InternalMarvin32HashString(this, this.Length, 0L);Как работает GetHashCode у делегатов
Прежде чем переходить к рассмотрению реализации метода GetHashCode у делегатов поговорим о том, как они реализованы.
Каждый делегат наследуется от класса MulticastDelegate, который в свою очередь наследуется от класса Delegate. Эта иерархия сложилась исторически, поскольку можно было бы обойтись одним классом MulticastDelegate.
Реализация метода GetHashCode в классе Delegate выглядит так
public override int GetHashCode()
{
return this.GetType().GetHashCode();
}Как известно, делегаты могут содержать цепочки методов, то есть вызов одного делегата приведет к вызову несколько методов, в таком случае такая реализация не годится так как у делегатов одного типа не зависимо от количества методов был бы один хеш-код, что не совсем хорошо, поэтому в MulticastDelegate метод GetHashCode переопредели таким образом, что он задействует каждый метод лежащий в основе делегата. Однако если количество методов и тип делегатов все же совпадают, то хеш-коды будут так же одинаковы.
Реализация метода в классе MulticastDelegate выглядит так
public override sealed int GetHashCode()
{
if (this.IsUnmanagedFunctionPtr())
return ValueType.GetHashCodeOfPtr(this._methodPtr) ^ ValueType.GetHashCodeOfPtr(this._methodPtrAux);
object[] objArray = this._invocationList as object[];
if (objArray == null)
return base.GetHashCode();
int num = 0;
for (int index = 0; index < (int) this._invocationCount; ++index)
num = num * 33 + objArray[index].GetHashCode();
return num;
}Если делегат содержит только один метод, то в коде выше objArray = null и соответственно хеш-код делегата будет равен хеш-коду типа делегата.
object[] objArray = this._invocationList as object[];
if (objArray == null)
return base.GetHashCode();Func<int> f1 = () => 1;
Func<int> f2 = () => 2;Func<int> f1 = () => 1;
Func<int> f2 = () => 2;
f1 += () => 3;
f2 += () => 4;int num = 0;
for (int index = 0; index < (int) this._invocationCount; ++index)
num = num * 33 + objArray[index].GetHashCode();
return num;Func<int> f1 = () => 1;
Func<int> f2 = () => 2;
f1 += () => 3;
f1 += () => 5;
f2 += () => 4;Как работает GetHashCode у анонимных типов
Как известно, анонимные типы — это новая фича в языке C# 3.0. Причем, это именно фича языка, так называемый синтаксический сахар поскольку CLR о них ничего не знает.
Метод GetHashCode у них переопределен таким образом, что использует каждое поле. Используя такую реализацию, два анонимных типа возвращают одинаковый хеш-код в том и только в том случае если их все поля равны. Такая реализация делает анонимные типы хорошо подходящими для ключей в хеш-таблицах.
var newType = new { Name = "Timur", Age = 20, IsMale = true };public override int GetHashCode()
{
return -1521134295 * (-1521134295 * (-1521134295 * -974875401 + EqualityComparer<string>.Default.GetHashCode(this.Name)) + EqualityComparer<int >.Default.GetHashCode(this.Age)) + EqualityComparer<bool>.Default.GetHashCode(this.IsMale);
}На заметку
Учитывая, что метод GetHashCode переопределен метод Equals, так же должен быть переопределен соответствующим образом.
var newType = new { Name = "Timur", Age = 20, IsMale = true };
var newType1 = new { Name = "Timur", Age = 20, IsMale = true };
if (newType.Equals(newType1))
Console.WriteLine("method Equals return true");
else
Console.WriteLine("method Equals return false");
if (newType == newType1)
Console.WriteLine("operator == return true");
else
Console.WriteLine("operator == return false");method Equals return true
operator == return false
Все дело в том, что анонимные типы переопределяют метод Equals таким образом, что он проверяет все поля как это сделано у ValueType (только без рефлексии), но не переопределяет оператор равенства. Таким образом, метод Equals сравнивает по значению, в то время как оператор равенства сравнивает по ссылкам.
Для чего надо было переопределять методы Equals и GetHashCode?
Учитывая, что анонимные типы были созданы для упрощения работы с LINQ, ответ становится понятным. Анонимные типы удобно использовать в качестве хеш-ключей в операциях группировки (group) и соединения (join) в LINQ.
На заметку
Заключение
Как видите генерация хеш-кодов — дело весьма не простое. Для того чтобы сгенерировать хорошие хеши, нужно приложить не мало усилий, и разработчикам CLR пришлось пойти на многие уступки, чтобы облегчить нам жизнь. Сгенерировать хеш-код хорошо, для всех случаев невозможно, поэтому лучше переопределять метод GetHashCode для ваших пользовательских типов, тем самым подстраивая их к конкретной вашей ситуации.
Спасибо за прочтение! Надеюсь, статья оказалось полезной.
Комментариев нет:
Отправить комментарий